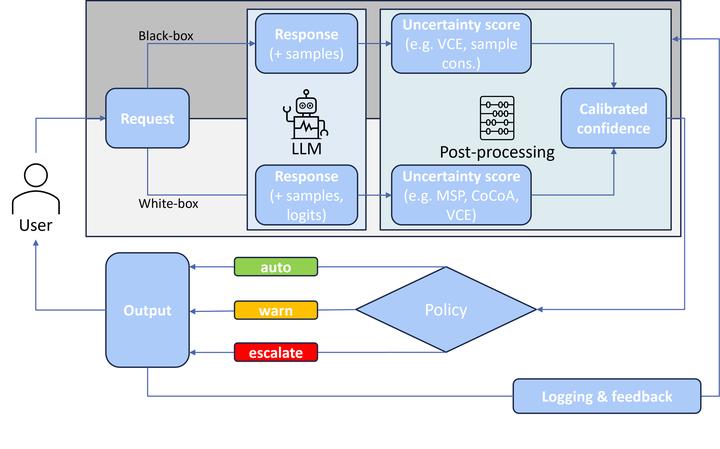
 Deployment pipeline including LLM Uncertainty Evaluation
Deployment pipeline including LLM Uncertainty Evaluation
Abstract
Large language models (LLMs) produce outputs with varying levels of uncertainty, and, just as often, varying levels of correctness; making their practical reliability far from guaranteed. To quantify this uncertainty, we systematically evaluate four approaches for confidence estimation in LLM outputs: VCE, MSP, Sample Consistency, and CoCoA (Vashurin et al., 2025). For the evaluation of the approaches, we conduct experiments on four question-answering tasks using a state-of-the-art open-source LLM. Our results show that each uncertainty metric captures a different facet of model confidence and that the hybrid CoCoA approach yields the best reliability overall, improving both calibration and discrimination of correct answers. We discuss the trade-offs of each method and provide recommendations for selecting uncertainty measures in LLM applications.
1. Introduction
LLMs are powerful but not reliably calibrated: high confidence does not always mean high correctness. For safety-critical or user-facing systems, we need well-calibrated confidence so downstream components (or users) can decide when to trust, defer, or verify a model’s output. This project systematically compares four uncertainty methods and reports what works best in practice.
2. Methods
2.1 Evaluated Approaches
- VCE (Variance of Confidence Estimates): Variability of confidence across perturbations/prompts.
- MSP (Maximum Softmax Probability): Uses the model’s top probability as a proxy for confidence.
- Sample Consistency: Measures agreement across sampled generations (e.g., different temperatures/seeds).
- CoCoA (Consensus-Consistency Aggregation): Hybrid method combining agreement signals and confidence scores (Vashurin et al., 2025).
2.2 Tasks and Model
- Tasks: Four question-answering benchmarks.
- Model: A state-of-the-art open-source LLM evaluated under a unified pipeline (same prompts, decoding settings, and scoring).
2.3 Metrics
- Calibration (e.g., ECE / reliability curves): How well predicted confidence matches empirical accuracy.
- Discrimination (e.g., AUROC for correctness detection): How well a score separates correct vs. incorrect answers.
3. Results
3.1 High-Level Findings
- Each method captures a distinct uncertainty signal:
- MSP is simple and strong but can be over-confident.
- VCE surfaces instability under prompt or sampling changes.
- Sample Consistency reflects agreement across generations.
- CoCoA outperforms others overall, improving both:
- Calibration (confidence aligns better with true accuracy),
- Discrimination (clearer separation of correct vs. incorrect answers).
3.2 Practical Trade-offs
- Cost vs. Accuracy: Methods requiring multiple samples (VCE, Sample Consistency, CoCoA) are more compute-intensive but yield better reliability.
- Simplicity vs. Robustness: MSP is trivial to deploy; CoCoA is more robust but requires orchestration of multiple signals.
4. Recommendations
- If you need a drop-in baseline: Start with MSP; monitor miscalibration and add temperature scaling if possible.
- If you can afford moderate overhead: Add Sample Consistency to catch brittle answers.
- For best reliability: Use CoCoA to combine agreement-based and score-based signals; prioritize it for user-facing or safety-critical deployments.
- Always visualize calibration (reliability plots) and track a correctness AUROC to ensure your uncertainty signal is meaningful.
5. Conclusion
Reliable LLM systems hinge on trustworthy confidence estimates. Our experiments show that while single-signal methods (MSP, VCE, Sample Consistency) provide useful but partial views, the hybrid CoCoA approach achieves the best overall reliability by combining signals. Teams should select a method that matches their latency/compute budget and risk profile, with CoCoA as the preferred option when reliability matters most.
Reference: Vashurin, R., Goloburda, M., Ilina, A., Rubashevskii, A., Nakov, P., Shelmanov, A., & Panov, M. (2025). Uncertainty Quantification for LLMs through Minimum Bayes Risk: Bridging Confidence and Consistency. arXiv preprint arXiv:2502.04964.
Christian Hobelsberger
Statistics Student at LMU Munich | Data Science at Munich Re
Statistics student at LMU Munich with a penchant for data science and chess!